
Imagine you have JSON data files and you want to load them into a DynamoDB table. How would you do that?
Probably DynamoDB Imports from S3 service is the first thing that you would consider. It creates a table with the data which makes it fast and cheap since you don’t have to pay for DynamoDB write APIs. However, it has a big limitation; you can’t use it for an existing table! That means if you use DynamoDB streams for your table to feed the changes to another function or if you already have data in your DynamoDB table and cannot afford deleting it, you are in trouble.
As another solution, AWS Data Pipeline could be used in such cases but it is discontinued as of 2022.
The good news is, AWS Glue can be used to load JSON files into DynamoDB tables -even the existing ones!
AWS Glue is a service that allows users to transfer data from one resource to another. It simply extracts data from the source, transforms it and then loads it to the target. This is commonly used as ETL: Extract, Transform, Load.
Glue supports a wide range of data sources, including databases, data lakes, and various file formats. Today we will inspect a scenario in which we have S3 as a data source, DynamoDB as target, and JSON as the data format.
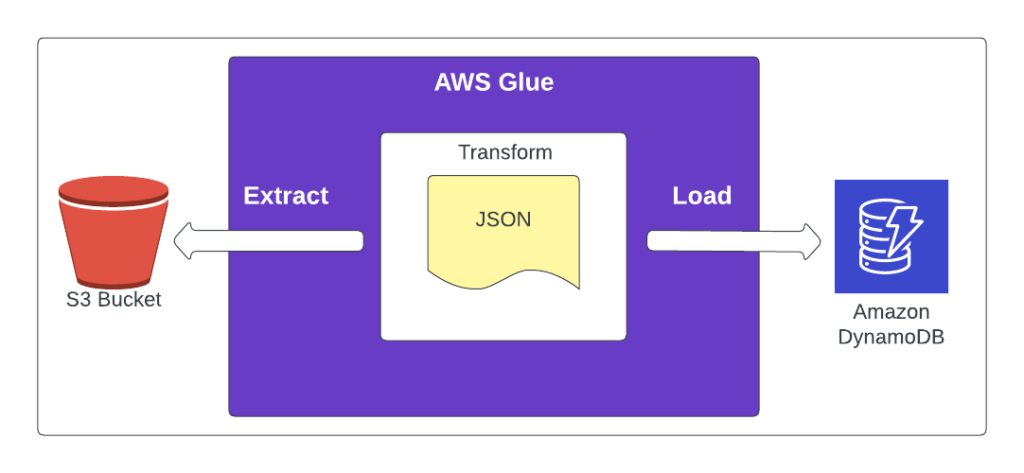
First create a Glue ETL job and select Spark script and create a new script.
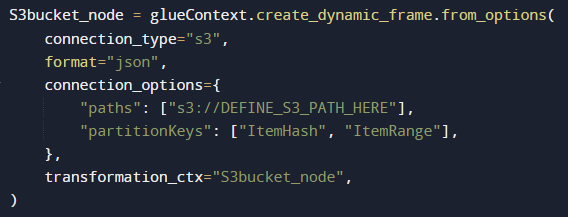
Then, create a dynamic frame for reading the S3 objects:
You can event transform the data if you need to:
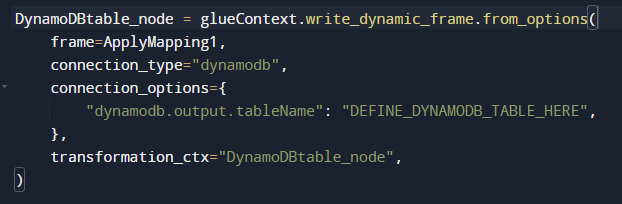
Then create a frame for writing the data to DynamoDB:
In summary, AWS Glue service can be used to load JSON files into existing DynamoDB tables efficiently. If you were a Data Pipeline user before, AWS Glue is your new friend. If you can afford to delete and re-create your DynamoDB table, DynamoDB Imports from S3 is the fastest and cheapest way to load your data.

